使用bert提取词向量
为了方便记忆做一下存档
提取词向量
bert的预训练模型可以直接拿来使用,目前成熟的库大概有两套,第一套是clip-as-service库,函数封装得很方便,可以直接传入生成句向量,但是无法生成词向量,所以还是直接拿torch手写吧。本文用到了pytorch和transformer库。
from transformers import BertTokenizer, BertModel
import torch
# 加载中文 BERT 模型和分词器
model_name = "bert-base-chinese"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)
首先预加载bert的中文预训练模型,初始化分词器,加载模型。
def get_word_embedding(sentence):
# 分词
tokens = tokenizer.tokenize(sentence)
# 添加特殊标记 [CLS] 和 [SEP]
tokens = ['[CLS]'] + tokens + ['[SEP]']
# 将分词转换为对应的编号
input_ids = tokenizer.convert_tokens_to_ids(tokens)
# 转换为 PyTorch tensor 格式
input_ids = torch.tensor([input_ids])
# 获取词向量
outputs = model(input_ids)
# outputs[0]是词嵌入表示
embedding = outputs[0]
# 去除头尾标记的向量值
word_embedding = embedding[:, 1:-1, :]
return word_embedding
在 BERT 模型中,每个词通过经过多层的自注意力和前馈神经网络的处理,生成一个高维的隐藏状态表示。这个隐藏状态表示包含了词在上下文中的语义信息,并被用于下游的自然语言处理任务,如文本分类、命名实体识别、句子匹配等。
隐藏状态的维度通常为 [batch_size, sequence_length, hidden_size],其中:
batch_size是输入文本的批次大小,即一次输入的文本样本数量。sequence_length是输入文本序列的长度,即编码器输入的词的数量。hidden_size是隐藏状态的维度大小,是 BERT 模型的超参数,通常为 768 或 1024。
因此,生成的词向量的维度也会是二维的,包含了每个词在输入文本序列中的表示。如果希望将词向量降维为一维,可以通过对隐藏状态进行适当的池化(如平均池化、最大池化等)或降维操作(如将隐藏状态展平为一维向量)来实现。
可以看到tokens = ['[CLS]'] + tokens + ['[SEP]']这一句的操作是将分词后的数组加上CLS标记和SEP标记,其中CLS作为整个句子的代表,如果需要提取句向量,那么输入模型后提取[CLS]对应的词向量即可代表句向量。
好了,现在看看提取出来的返回值是什么
emb = get_word_embedding("我喜欢吃水果")
print(emb.shape)
返回结果:

可以看到,返回的是一个三维矩阵,其中第一个维度代表着对应的batchsize,第二个为输入词数量,而最后一个就是每个词对应的隐藏层的向量。
比较句相似度
有了上面的经验,就可以直接写句子相似度的函数了:
def compare_sentence(sentence1, sentence2):
# 分词
tokens1 = tokenizer.tokenize(sentence1)
tokens2 = tokenizer.tokenize(sentence2)
# 添加特殊标记 [CLS] 和 [SEP]
tokens1 = ['[CLS]'] + tokens1 + ['[SEP]']
tokens2 = ['[CLS]'] + tokens2 + ['[SEP]']
# 将分词转换为对应的编号
input_ids1 = tokenizer.convert_tokens_to_ids(tokens1)
input_ids2 = tokenizer.convert_tokens_to_ids(tokens2)
# 转换为 PyTorch tensor 格式
input_ids1 = torch.tensor([input_ids1])
input_ids2 = torch.tensor([input_ids2])
# 获取词向量
outputs1 = model(input_ids1)
outputs2 = model(input_ids2)
# outputs[0]是词嵌入表示
embedding1 = outputs1[0]
embedding2 = outputs2[0]
# 提取 [CLS] 标记对应的词向量作为整个句子的表示
sentence_embedding1 = embedding1[:, 0, :]
sentence_embedding2 = embedding2[:, 0, :]
# 计算词的欧氏距离
euclidean_distance = torch.nn.PairwiseDistance(p=2)
distance = euclidean_distance(sentence_embedding1, sentence_embedding2)
# 计算余弦相似度
cos = torch.nn.CosineSimilarity(dim=1, eps=1e-6)
similarity = cos(sentence_embedding1, sentence_embedding2)
print("句1: ", sentence1)
print("句2: ", sentence2)
print("相似度: ", similarity.item())
print("欧式距离: ", distance.item())
其中能想到最直观的近似方法,既然是向量,那当然用cosine表示相关度最好了。当然也算了一下绝对距离。
compare_sentence("我喜欢吃水果", "今天的天气糟透了")
该行代码执行完成后返回了如下结果
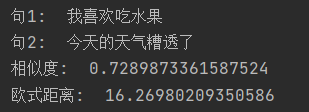
按理来说这两个八竿子打不着的句子应该没什么关联度。但是事实上bert的向量分布就是这样密集,具体原因如下:
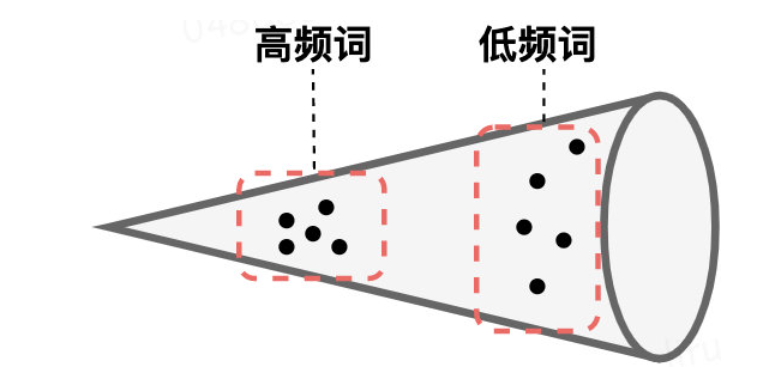
- BERT的词向量在空间中不是均匀分布,而是呈锥形。BERT-FLOW的作者发现高频词都靠近原点(所有的均值),而低频词远离原点,相当于这两种词处于了空间中不同的区域,那高频词和低频词之间的相似度就不再适用了
- 低频词的分布很稀疏。低频词表示得到的训练不充分,分布稀疏,导致该区域存在语义定义不完整的地方(poorly defined),这样算出来的相似度也有问题。
这个观点来自BERT-FLOW论文的作者,当然如果只是因为分布不均再引入一层FLOW,会很麻烦。
总体来说,我们希望使得学习算法的输入具有如下性质:特征之间相关性较低;所有特征具有相同的方差,所以后来发现了另外一个方法:
作者通过简单的坐标正交的方法(作者称之为白化)将BERT模型得到的锥形向量分布平均地映射到了正交坐标空间。