推荐技术栈
推荐系统技术栈
总体技术流程
- TODO
模型构建过程
实体抽取
- NER任务+BERT FINE-TUNE
模型选取:BERT-BiLSTM-CRF&&ALBERT-BiLSTM-CRF
备选模型&&消融实验对象:
- HMM隐马尔科夫场模型
- LSTM-CRF 长短期记忆+条件随机场
- BiLSTM-CRF 双向长短期记忆+条件随机场
从目前的推理效果来看不尽人意,但是很大一部分原因在于数据集构建和分割存在问题。
后续需要继续抽取实验。
- 字典抽取数据集
从短期项目上可行性很高,从长期技术栈规划上看,字典抽取为承担一部分实体抽取的任务,但是实际上,从短期项目上线的实现上看,字典抽取可以完成整个知识图谱构建的部分。
关系抽取
传统抽取方法:规则匹配
主要实现技术栈为BERT+句子级别ATTENTION,考虑到实体抽取部分也会用到BERT,所以优先选择BERT相关的模型。
备用模型:
- SPERT
- ETL-SPAN
- CASREL
图谱构建
构建模式层
首先构建模式层,规定好图谱的语义层,通过模式去收集数据并且对齐数据层面,也就是数据和数据之间的联系。
数据层构建
数据层可以看作关系抽取和实体抽取之后得到的产物,数据层不仅是作为类比推荐的核心推理依据,也是关系抽取和实体抽取之后的产物,如果要撰写论文,除了后端方面的应用,数据层的构建的方法论应当作为核心中的核心。
推荐过程
关键词抽取
技术栈选取
- 通过过滤字典的方法寻找到关键词的相关领域,此流程为纯字典方法构建推荐系统的流程图,字典构建也可嵌入到NLP任务中,作为关键词提取的前置任务。
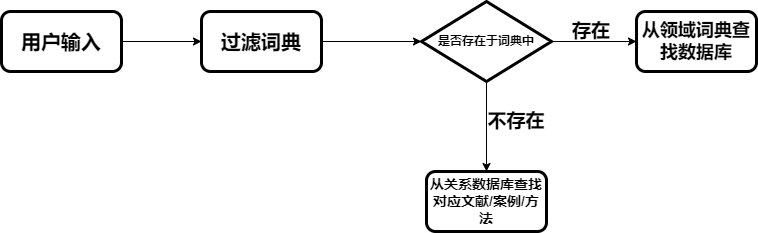
- NLP抽取词向量
抽取词向量后,以最近似方法选取词向量最接近的数据库中的实体或关系;此处的流程为:使用隐马尔科夫链(如果实体抽取效果并不好)和实体抽取模型抽取目标实体。向量化该实体—此过程为本类型实体的最近似抽取;第二步,选取最近似向量的关系实体,作为目标推荐实体,目的为–譬如用户搜寻了湖北省,通过实体命名识别后,发现用户需求为省份相关的资料,那么首先选取湖北省关联的实体–文献、案例、方法 等,再选取与湖北省相近—时空相近或者地层类型相近的地区,再选取它们作为权重较低的搜索结果返回。