BERT会说话吗?
一个想法
以GPT为代表的自回归预训练语言模型有着惊人的文本补全能力。这种通用能力来自它的预训练任务Next Token Predict,即下一词预测任务。那BERT能做到这样的事吗?众所周知,BERT的预训练任务是MLM(完形填空)和NSP(下一句预测),这种预训练任务和NTP不同,可能无法做生成式的任务。是吗?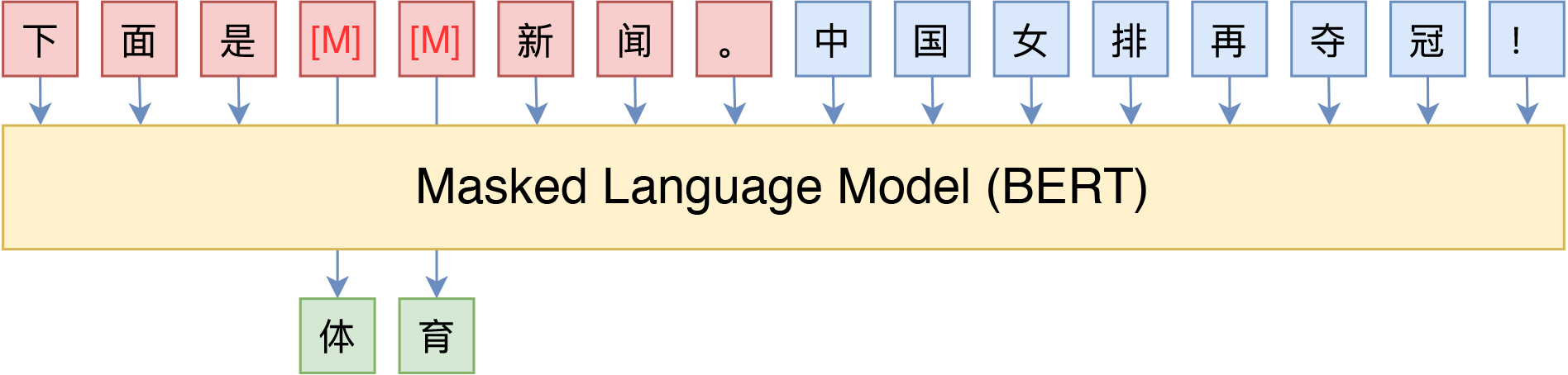
想法1:自回归地在句子结尾添加MASK
一个很自然的想法,既然GPT的任务是对下一个词的预测,那么,使用BERT在需要生成的句子后面添加[MASK],然后使用BERT模型预测这个MASK,是否就能将其转化为自回归的生成任务呢?我们对BERT语言模型的预期如下所示:
原始文本:你好,我的名字是
递归式地添加遮罩:
你好,我的名字是[MASK] -> 你好,我的名字是李
你好,我的名字是李[MASK] -> 你好,我的名字是李华
你好,我的名字是李华[MASK] -> 你好,我的名字是李华。为了实现以上功能,使用Transformers库快速实现了以下代码:
from transformers import pipeline
fill_masker = pipeline(model="hfl/chinese-bert-wwm")
sequence = '你好,我的名字是'
while len(sequence) <= 32:
result = fill_masker(f"{sequence}[MASK]")
sequence = result[0]['sequence']
print(sequence)限制输出为32个token,每次在最后面添加mask,然后让bert预测被掩盖的部分。(为了简化流程,这里直接使用transformers库封装的pipline)。
实验结果
输入: 你好,我的名字是
输出:你 好 , 我 的 名 字 是 : 。 。 。 。 。 。 。 。
多次尝试后结果均如此。可以观测到的是,使用BERT进行预测的时候,BERT更倾向于快速结束这个句子。可以说明,这个想法行不通。
想法2:从遮罩里全随机恢复出句子
想法1行不通其实是可以理解的。对于BERT的训练集来说,当一个句子的最后一个词被MASK后,BERT会自然而然地认为这个词是一个句子的最后一个字,并且试图将常出现在自然语言句子结尾处的词恢复出来,那么,当然它就有结束这个句子的倾向,在想法1的实验结果中,发现BERT非常喜欢输出句号。这是BERT预训练的任务特点决定的。
那么,我们一开始就准备好所有MASK,让模型从MASK中一步一步预测出句子,如何呢?我的预期是这样的:
原始文本:[MASK][MASK][MASK][MASK][MASK][MASK][MASK][MASK][MASK][MASK][MASK]
1. 将MASK顺序打乱,然后随机预测(为了符合BERT的预训练任务)
2. 按顺序预测MASK,最终输出句子。为了完成上面的任务,编写了以下代码实现:
class BertGenerator:
def __init__(self, model_name='bert-base-chinese'):
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForMaskedLM.from_pretrained(model_name).to(self.device)
self.model.eval()
def generate(self, length=10, top_k=5, temperature=1.0, random_order=True):
"""
生成随机文本。
Args:
length (int): 生成文本的长度,不包括CLS和SEP标记。默认为10。
top_k (int): 在生成的每一步中,从预测的词汇中选择前top_k个概率最高的词汇。默认为5。
temperature (float): 控制生成文本的随机性。温度越高,生成的文本越随机。默认为1.0。
random_order (bool): 是否随机打乱生成顺序。默认为True。
Returns:
str: 生成的随机文本字符串。
"""
tokens = ['[CLS]'] + ['[MASK]'] * length + ['[SEP]']
input_ids = self.tokenizer.convert_tokens_to_ids(tokens)
input_ids = torch.tensor([input_ids]).to(self.device)
positions = list(range(1, length + 1))
if random_order:
random.shuffle(positions)
for pos in positions:
with torch.no_grad():
outputs = self.model(input_ids)
predictions = outputs.logits
masked_predictions = predictions[0, pos]
masked_predictions = masked_predictions / temperature
top_k_probs, top_k_indices = torch.topk(F.softmax(masked_predictions, dim=-1), top_k)
selected_idx = torch.multinomial(top_k_probs, 1)
predicted_token_id = top_k_indices[selected_idx].item()
input_ids[0, pos] = predicted_token_id
generated_text = self.tokenizer.decode(input_ids[0][1:-1])
return generated_text
if __name__ == "__main__":
generator = BertGenerator()
for _ in range(10):
sentence = generator.generate(32,ranom_order=False)
print(sentence)我们首先生成十个随机句子,规定token长度是32。
采样结果如下所示(顺序恢复):
、 ( ( ) ( , , 是 、 , 、 、 、 和 , ( , ) , 是 一 位 美 國 電 視 電 影 配 音 員 。
, 。 , , 。 《 》 , 《 [UNK] 》 , , , , , , , , , , , , , , , , , , , , 。
, 。 、 , 是 , 。 的 在 , 在 在 在 在 的 的 的 在 在 , 在 在 在 在 的 。 在 , 在 在 在 在
, , 的 。 。 , 在 在 的 [UNK] [UNK] [UNK] 是 [UNK] [UNK] 的 [UNK] [UNK] 。 , 的 , 。 , 在 在 [UNK] [UNK] [UNK] 是 [UNK] [UNK]
, , 。 《 [UNK] , 《 [UNK] [UNK] 》 , 《 [UNK] [UNK] 》 [UNK] [UNK] [UNK] , [UNK] [UNK] [UNK] 》 , [UNK] [UNK] [UNK] , [UNK] [UNK] [UNK] 》
, , 的 《 的 。 , 《 》 《 《 , 《 , [UNK] , [UNK] [UNK] [UNK] 的 [UNK] [UNK] [UNK] , [UNK] [UNK] [UNK] 的 , [UNK] [UNK] [UNK]
、 ( 、 是 , 是 , , 《 》 , , , [UNK] , [UNK] , , , , , [UNK] , , 和 , [UNK] , ( ) [UNK] ,
, 。 。 , , , , , , , , 和 [UNK] [UNK] [UNK] 是 [UNK] 非 阿 [UNK] , [UNK] [UNK] 是 [UNK] 非 阿 [UNK] 。 , , ,
《 , 。 在 , 的 , 是 , 。 是 , , 是 , , 是 。 在 , , 的 。 在 , 的 , 是 , 》 是 。
《 , 。 , 。 是 、 , 。 , , , , , , , , , , , 》 ( 布 爾 登 高 高 高 高 高 高 高乱序恢复的结果如下所示:
。 [UNK] [UNK] 、 [UNK] [UNK] 、 在 中 的 [UNK] [UNK] , [UNK] [UNK] , 在 在 中 的 [UNK] [UNK] 。 。 。 [UNK] [UNK] 、 [UNK] [UNK] 。 。
, 、 、 、 , 、 , [UNK] [UNK] 、 、 , , [UNK] 、 [UNK] [UNK] [UNK] , 、 , [UNK] [UNK] , ( ) 、 [UNK] [UNK] , [UNK] [UNK]
。 [UNK] 。 [UNK] , [UNK] [UNK] , [UNK] [UNK] , [UNK] , [UNK] , [UNK] , [UNK] , , [UNK], [UNK] 也 也 也 也 也 也 也 , [UNK]
[UNK] , [UNK] [UNK] , [UNK] , [UNK] : [UNK] , [UNK] [UNK] , [UNK] : [UNK] : [UNK] , 。 。 , , 。 , , 。 。 , 。 。
[UNK] [UNK] 下 , [UNK] 中 , [UNK] [UNK] 中 , [UNK] [UNK] [UNK] [UNK] , [UNK] [UNK] 中 , [UNK] [UNK] , [UNK] [UNK] 上 , [UNK] [UNK] 中 。 中
。 。 、 [UNK] 、 [UNK] 、 。 [UNK] 、 。 [UNK] 、 [UNK] 。 [UNK] 。 [UNK] 的 , [UNK] 。 [UNK] 的 。 [UNK] [UNK] [UNK] , [UNK] 。 。
[UNK] 、 , 、 ( [UNK] [UNK] [UNK] ) 、 , [UNK] 、 、 、 、 、 [UNK] 、 、 、 [UNK] 、 [UNK] 、 , ( 一 字 [UNK] ) 。
。 、 、 。 , ( [UNK] [UNK] ) 一 、 。 。 , , 。 , ( [UNK] [UNK] [UNK] [UNK] ) [UNK] , ( [UNK] [UNK] 、 [UNK] ) 。
。 中 , [UNK] : [UNK] 中 。 [UNK] , [UNK] [UNK] : [UNK] , [UNK] 。 中 , [UNK] 。 中 , [UNK] 中 , [UNK] 。 [UNK] 。 中 ,
。 [UNK] , , , 。 。 [UNK] , 。 [UNK] , , , 。 [UNK] : 。 [UNK] , [UNK] , 。 [UNK] : , , , 。 [UNK] , ,观察到了一些可以用的句子,但是整体来看,从随机空间里采样数据看起来是不对的,这里可能是因为没有去除特殊标记的词表。
重新修改代码之后运行:
输入:16个[MASK]
顺序采样:
, 年 年 の 年 は 、 人 生 か 最 終 の 時 期 。
, , , , 、 、 、 , , , , , , , , 。
的 年 月 日 月 的 日 日 月 月 日 月 日 日 日 。
、 年 に 、 、 年 に 、 、 、 年 に 、 、 年 。
的 月 産 産 産 産 的 的 的 是 在 的 月 産 産 !
。 。 人 か 人 か 人 か 人 か 。 人 か 人 か 。
! 的 は のの 中 は 中 て 、 なせかの 中 !
。 。 中 に 中 て 自 分 に 出 す 人 か 。 。 。
。 、 、 、 ににに 、 ににに 。 、 、 , 。
, 人 の 体 を 、 それを 、 し 、 と 、 と 。
乱序采样:
的 式 の 中 に 通 り 、 の 式 は 正 面 の 上 。
、 一 人 なのて 、 今 は 現 代 人 の 中 の 仕 事 。
月 月 月 月 年 。 月 月 月 月 年 年 月 。 月 。
, 。 本 人 は 青 年 の 方 か 目 とか 。 , 。
中 国 の 親 子 の 私 の 親 子 ・ 私 の 菓 子 。
。 私 に 会 う 人 は 、 それても 私 は の 人 。
人 は 心 に 、 自 己 は 心 のない 、 心 かない 。
。 子 の 子 の 子 は 、 子 子 の 子 子 女 の 。
一 年 は 年 の 日 、 日 子 の 日 、 日 の 日 。
中 国 の 国 は 本 国 の 国 の 存 在 的 の 内 的怎么连日文都干出来了?
想法3:一半输入,一半补全
基于前两个尝试的折中,用户规定一半的输入,再规定一半的[MASK]让模型补全,看起来像这样:
原始文本:你好,我叫[MASK][MASK][MASK][MASK][MASK][MASK]
1. 将MASK顺序打乱,然后随机预测
2. 按顺序预测MASK,最终输出句子。这里就不贴代码了,和前面差不多。最后我会贴上全部代码。
输入:你好,我的名字叫[MASK][MASK][MASK][MASK]
顺序采样:
你 好 , 我 的 名 字 叫 : 刘 天 。
你 好 , 我 的 名 字 叫 李 天 天 。
你 好 , 我 的 名 字 叫 王 一 平 。
你 好 , 我 的 名 字 叫 李 小 红 。
你 好 , 我 的 名 字 叫 李 小 冰 。
你 好 , 我 的 名 字 叫 : 李 一 。
你 好 , 我 的 名 字 叫 王 小 冰 !
你 好 , 我 的 名 字 叫 李 老 师 ,
你 好 , 我 的 名 字 叫 小 小 甜 。
你 好 , 我 的 名 字 叫 : 李 一 。
乱序采样:
你 好 , 我 的 名 字 叫 阿 也 拉 。
你 好 , 我 的 名 字 叫 张 国 华 。
你 好 , 我 的 名 字 叫 我 儿 子 。
你 好 , 我 的 名 字 叫 小 小 豆 。
你 好 , 我 的 名 字 叫 xyg 。
你 好 , 我 的 名 字 叫 : 姚 明 。
你 好 , 我 的 名 字 叫 jacky ' s
你 好 , 我 的 名 字 叫 李 文 明 。
你 好 , 我 的 名 字 叫 阿 哈 哈 。
你 好 , 我 的 名 字 叫 tatao 。从这里开始,我们可以看到,预测的结果已经不错,说明对于比较短的MASK,BERT已经可以得出好的结果,那么如果长一点呢?
输入:你好,我的名字叫[MASK][MASK][MASK][MASK][MASK][MASK][MASK]
顺序采样:
你 好 , 我 的 名 字 叫 " 大 大 的 小 猫 " 。
你 好 , 我 的 名 字 叫 你 , 我 的 爱 叫 爱 。
你 好 , 我 的 名 字 叫 " 小 小 的 小 鱼 " 。
你 好 , 我 的 名 字 叫 你 , 你 叫 我 什 么 ?
你 好 , 我 的 名 字 叫 " 阿 里 " , 是 吗 ?
你 好 , 我 的 名 字 叫 「 カッチャー 」 !
你 好 , 我 的 名 字 叫 「 カラーキャン 。
你 好 , 我 的 名 字 叫 「 大 叔 」 , 好 嗎 ?
你 好 , 我 的 名 字 叫 「 大 叔 」 。 好 啦 。
你 好 , 我 的 名 字 叫 " 阿 尔 巴 尼 亚 " 。
乱序采样:
你 好 , 我 的 名 字 叫 张 小 龙 , 张 小 龙 。
你 好 , 我 的 名 字 叫 藤 田 丹 ( とん ) 。
你 好 , 我 的 名 字 叫 阿 明 ( o - chan ) 。
你 好 , 我 的 名 字 叫 做 " 慧 光 " 大 师 。
你 好 , 我 的 名 字 叫 " 亲 爱 的 孩 子 " 。
你 好 , 我 的 名 字 叫 xxx , 今 年 12 岁 的 。
你 好 , 我 的 名 字 叫 张 小 姐 , 张 大 姐 。
你 好 , 我 的 名 字 叫 做 我 的 小 女 朋 友 。
你 好 , 我 的 名 字 叫 可 爱 的 小 雪 人 哦 !
你 好 , 我 的 名 字 叫 月 華 , 愛 的 是 你 。模型会因为MASK的增长,而逐渐失去预测的效果,但是比起前几个实验,效果提升了很多。
想法4:从整个句子中采样出另外一个句子
那么,如果我们输入随机句子,然后让模型将句子的每一个token全部重新采样一遍,会怎么样呢?
输入:你好,我的名字叫李华,来自湖北武汉。
顺序采样:
您 好! 您 的 名 字 叫 小 燕, 来 自 湖 北 武 汉 !
您 好 : 您 的 名 字 叫 刘 强 , 来 自 湖 北 武 汉 。
您 好! 我 的 名 字 叫 小 燕, 来 自 湖 北 武 昌 。
你 好 , 我 的 名 字 叫 小 马 。 来 自 湖 北 武 汉 。
您 好 : 你 的 名 字 是 刘 伟 , 来 自 湖 北 武 汉 。
您 好 : 您 的 名 字 叫 刘 强 , 来 自 湖 北 武 汉 。
您 好 : 您 的 名 字 是 张 伟 , 来 自 湖 北 武 汉 。
您 好 : 您 的 名 字 叫 张 某 , 来 自 湖 北 武 汉 。
您 好 , 您 的 名 字 叫 张 勇 , 来 自 湖 北 武 汉 。
您 好! 你 的 名 字 叫 王 伟 。 来 自 湖 北 武 汉 。
乱序采样:
您 好 , 您 的 名 字 叫 刘 涛 。 来 自 湖 北 武 昌 。
您 好, 你 的 名 字 是 张 涛 , 来 自 湖 北 武 汉 。
您 好 : 您 的 名 字 是 刘 强 , 来 自 湖 北 宜 昌 。
您 好, 你 的 名 字 叫 刘 明 。 来 自 湖 北 武 穴 。
您 好 : 你 的 名 字 叫 张 波 , 来 自 湖 北 宜 昌 。
您 好 , 你 的 名 字 叫 张 静 , 来 自 湖 北 武 汉 。
你 看 , 我 的 名 字 叫 小 明 , 来 自 湖 北 宜 昌 。
您 好 : 您 的 名 字 叫 刘 强, 来 自 湖 北 武 汉 。
您 好 , 你 的 名 字 是 小 静 , 来 自 湖 北 武 汉 。
你 好 , 你 的 名 字 是 张 敏 , 来 自 湖 北 武 汉 。看起来效果很不错。
结论
BERT对于生成式任务来说,在理论上来说,是完全可行的
对生成任务的几种尝试,说明BERT依然更适合做文本补全的任务,而不是文本生成。
BERT会说话,但是让它说话更像是捂着它的嘴巴发声。

完整代码
import random
import torch
from transformers import AutoTokenizer, AutoModelForMaskedLM
import torch.nn.functional as F
class BertGenerator:
def __init__(self, model_name='bert-base-chinese'):
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForMaskedLM.from_pretrained(model_name).to(self.device)
self.model.eval()
def generate_text_from_input(self, input_text, max_token_size=32, top_k=5, temperature=1.0,random_order=True):
token_lens = len(self.tokenizer.tokenize(input_text))
left_size = max_token_size - token_lens
if left_size <0:
return None
tokens = ['[CLS]'] + self.tokenizer.tokenize(input_text) + ['[MASK]'] * left_size + ['[SEP]']
input_ids = self.tokenizer.convert_tokens_to_ids(tokens)
input_ids = torch.tensor([input_ids]).to(self.device)
# 真实文本的位置
positions = list(range(1 + token_lens , len(tokens) - 1))
if random_order:
random.shuffle(positions)
for pos in positions:
original_token_id = input_ids[0, pos].item()
input_ids[0, pos] = self.tokenizer.mask_token_id
with torch.no_grad():
outputs = self.model(input_ids)
predictions = outputs.logits
masked_predictions = predictions[0, pos]
masked_predictions = masked_predictions / temperature
top_k_probs, top_k_indices = torch.topk(F.softmax(masked_predictions, dim=-1), top_k)
selected_idx = torch.multinomial(top_k_probs, 1)
predicted_token_id = top_k_indices[selected_idx].item()
retry_count = 0
while predicted_token_id == original_token_id and retry_count < 3:
selected_idx = torch.multinomial(top_k_probs, 1)
predicted_token_id = top_k_indices[selected_idx].item()
retry_count += 1
input_ids[0, pos] = predicted_token_id
generated_text = self.tokenizer.decode(input_ids[0][1:-1])
return generated_text
def generate_text_from_input_without_unk(self, input_text, max_token_size=32, top_k=5, temperature=1.0, random_order=True):
"""
基于输入文本生成新文本,避免生成UNK和特殊标记。
Args:
input_text (str): 输入的文本。
max_token_size (int): 最大标记数量。
top_k (int): 在生成的每一步中,从预测的词汇中选择前top_k个概率最高的词汇。
temperature (float): 控制生成文本的随机性。温度越高,生成的文本越随机。
random_order (bool): 是否随机打乱生成顺序。
Returns:
str: 生成的文本字符串。
"""
# 获取特殊标记的ID
special_tokens_ids = set([
self.tokenizer.unk_token_id,
self.tokenizer.pad_token_id,
self.tokenizer.mask_token_id,
self.tokenizer.cls_token_id,
self.tokenizer.sep_token_id
])
# 计算输入文本的token长度
token_lens = len(self.tokenizer.tokenize(input_text))
left_size = max_token_size - token_lens
if left_size < 0:
return None
tokens = ['[CLS]'] + self.tokenizer.tokenize(input_text) + ['[MASK]'] * left_size + ['[SEP]']
input_ids = self.tokenizer.convert_tokens_to_ids(tokens)
input_ids = torch.tensor([input_ids]).to(self.device)
# 获取需要生成的位置
positions = list(range(1 + token_lens, len(tokens) - 1))
if random_order:
random.shuffle(positions)
for pos in positions:
original_token_id = input_ids[0, pos].item()
input_ids[0, pos] = self.tokenizer.mask_token_id
with torch.no_grad():
outputs = self.model(input_ids)
predictions = outputs.logits
masked_predictions = predictions[0, pos]
# 创建掩码来过滤特殊标记
valid_tokens_mask = torch.ones_like(masked_predictions, dtype=torch.bool)
for special_id in special_tokens_ids:
valid_tokens_mask[special_id] = False
# 只在有效标记中进行选择
masked_predictions = masked_predictions / temperature
masked_predictions[~valid_tokens_mask] = float('-inf') # 将特殊标记的概率设为负无穷
# 在有效标记中选择top_k
top_k_probs, top_k_indices = torch.topk(F.softmax(masked_predictions, dim=-1),
min(top_k, valid_tokens_mask.sum().item()))
# 避免生成与原始标记相同的标记
selected_idx = torch.multinomial(top_k_probs, 1)
predicted_token_id = top_k_indices[selected_idx].item()
retry_count = 0
while predicted_token_id == original_token_id and retry_count < 3:
selected_idx = torch.multinomial(top_k_probs, 1)
predicted_token_id = top_k_indices[selected_idx].item()
retry_count += 1
input_ids[0, pos] = predicted_token_id
generated_text = self.tokenizer.decode(input_ids[0][1:-1])
return generated_text
def regenerate_from_input(self, input_text, top_k=5, temperature=1.0, random_order=True):
"""
根据输入文本重新生成文本。
Args:
input_text (str): 输入的文本字符串。
top_k (int, optional): 从预测的词汇中选择前top_k个概率最高的词汇。默认值为5。
temperature (float, optional): 控制生成文本的随机性。温度越高,生成的文本越随机。默认值为1.0。
random_order (bool, optional): 是否随机打乱输入文本中的词汇顺序。默认值为True。
Returns:
str: 重新生成的文本字符串。
"""
tokens = ['[CLS]'] + self.tokenizer.tokenize(input_text) + ['[SEP]']
input_ids = self.tokenizer.convert_tokens_to_ids(tokens)
input_ids = torch.tensor([input_ids]).to(self.device)
positions = list(range(1, len(tokens) - 1))
if random_order:
random.shuffle(positions)
for pos in positions:
original_token_id = input_ids[0, pos].item()
input_ids[0, pos] = self.tokenizer.mask_token_id
with torch.no_grad():
outputs = self.model(input_ids)
predictions = outputs.logits
masked_predictions = predictions[0, pos]
masked_predictions = masked_predictions / temperature
top_k_probs, top_k_indices = torch.topk(F.softmax(masked_predictions, dim=-1), top_k)
selected_idx = torch.multinomial(top_k_probs, 1)
predicted_token_id = top_k_indices[selected_idx].item()
retry_count = 0
while predicted_token_id == original_token_id and retry_count < 3:
selected_idx = torch.multinomial(top_k_probs, 1)
predicted_token_id = top_k_indices[selected_idx].item()
retry_count += 1
input_ids[0, pos] = predicted_token_id
generated_text = self.tokenizer.decode(input_ids[0][1:-1])
return generated_text
def regenerate_from_input_without_UNK(self, input_text, top_k=5, temperature=1.0, random_order=True):
"""
根据输入文本重新生成文本,避免生成UNK和特殊标记。
Args:
input_text (str): 输入的文本字符串。
top_k (int): 从预测的词汇中选择前top_k个概率最高的词汇。默认值为5。
temperature (float): 控制生成文本的随机性。温度越高,生成的文本越随机。默认值为1.0。
random_order (bool): 是否随机打乱输入文本中的词汇顺序。默认值为True。
Returns:
str: 重新生成的文本字符串。
"""
# 获取特殊标记的ID
special_tokens_ids = set([
self.tokenizer.unk_token_id,
self.tokenizer.pad_token_id,
self.tokenizer.mask_token_id,
self.tokenizer.cls_token_id,
self.tokenizer.sep_token_id
])
tokens = ['[CLS]'] + self.tokenizer.tokenize(input_text) + ['[SEP]']
input_ids = self.tokenizer.convert_tokens_to_ids(tokens)
input_ids = torch.tensor([input_ids]).to(self.device)
positions = list(range(1, len(tokens) - 1))
if random_order:
random.shuffle(positions)
for pos in positions:
original_token_id = input_ids[0, pos].item()
input_ids[0, pos] = self.tokenizer.mask_token_id
with torch.no_grad():
outputs = self.model(input_ids)
predictions = outputs.logits
masked_predictions = predictions[0, pos]
# 创建掩码来过滤特殊标记
valid_tokens_mask = torch.ones_like(masked_predictions, dtype=torch.bool)
for special_id in special_tokens_ids:
valid_tokens_mask[special_id] = False
# 只在有效标记中进行选择
masked_predictions = masked_predictions / temperature
masked_predictions[~valid_tokens_mask] = float('-inf') # 将特殊标记的概率设为负无穷
# 在有效标记中选择top_k
top_k_probs, top_k_indices = torch.topk(F.softmax(masked_predictions, dim=-1),
min(top_k, valid_tokens_mask.sum().item()))
# 避免生成与原始标记相同的标记
selected_idx = torch.multinomial(top_k_probs, 1)
predicted_token_id = top_k_indices[selected_idx].item()
retry_count = 0
while predicted_token_id == original_token_id and retry_count < 5:
selected_idx = torch.multinomial(top_k_probs, 1)
predicted_token_id = top_k_indices[selected_idx].item()
retry_count += 1
input_ids[0, pos] = predicted_token_id
generated_text = self.tokenizer.decode(input_ids[0][1:-1])
return generated_text
def generate(self, length=10, top_k=5, temperature=1.0, random_order=True):
"""
生成随机文本。
Args:
length (int): 生成文本的长度,不包括CLS和SEP标记。默认为10。
top_k (int): 在生成的每一步中,从预测的词汇中选择前top_k个概率最高的词汇。默认为5。
temperature (float): 控制生成文本的随机性。温度越高,生成的文本越随机。默认为1.0。
random_order (bool): 是否随机打乱生成顺序。默认为True。
Returns:
str: 生成的随机文本字符串。
"""
tokens = ['[CLS]'] + ['[MASK]'] * length + ['[SEP]']
input_ids = self.tokenizer.convert_tokens_to_ids(tokens)
input_ids = torch.tensor([input_ids]).to(self.device)
positions = list(range(1, length + 1))
if random_order:
random.shuffle(positions)
for pos in positions:
with torch.no_grad():
outputs = self.model(input_ids)
predictions = outputs.logits
masked_predictions = predictions[0, pos]
masked_predictions = masked_predictions / temperature
top_k_probs, top_k_indices = torch.topk(F.softmax(masked_predictions, dim=-1), top_k)
selected_idx = torch.multinomial(top_k_probs, 1)
predicted_token_id = top_k_indices[selected_idx].item()
input_ids[0, pos] = predicted_token_id
generated_text = self.tokenizer.decode(input_ids[0][1:-1])
return generated_text
def generate_without_UNK_token(self, length=10, top_k=5, temperature=1.0, random_order=True):
"""
生成随机文本,避免生成UNK和特殊标记。
Args:
length (int): 生成文本的长度,不包括CLS和SEP标记。默认为10。
top_k (int): 在生成的每一步中,从预测的词汇中选择前top_k个概率最高的词汇。默认为5。
temperature (float): 控制生成文本的随机性。温度越高,生成的文本越随机。默认为1.0。
random_order (bool): 是否随机打乱生成顺序。默认为True。
Returns:
str: 生成的随机文本字符串。
"""
# 获取特殊标记的ID
special_tokens_ids = set([
self.tokenizer.unk_token_id,
self.tokenizer.pad_token_id,
self.tokenizer.mask_token_id,
self.tokenizer.cls_token_id,
self.tokenizer.sep_token_id
])
tokens = ['[CLS]'] + ['[MASK]'] * length + ['[SEP]']
input_ids = self.tokenizer.convert_tokens_to_ids(tokens)
input_ids = torch.tensor([input_ids]).to(self.device)
positions = list(range(1, length + 1))
if random_order:
random.shuffle(positions)
for pos in positions:
with torch.no_grad():
outputs = self.model(input_ids)
predictions = outputs.logits
masked_predictions = predictions[0, pos]
# 创建掩码来过滤特殊标记
valid_tokens_mask = torch.ones_like(masked_predictions, dtype=torch.bool)
for special_id in special_tokens_ids:
valid_tokens_mask[special_id] = False
# 只在有效标记中进行选择
masked_predictions = masked_predictions / temperature
masked_predictions[~valid_tokens_mask] = float('-inf') # 将特殊标记的概率设为负无穷
# 在有效标记中选择top_k
top_k_probs, top_k_indices = torch.topk(F.softmax(masked_predictions, dim=-1),
min(top_k, valid_tokens_mask.sum().item()))
selected_idx = torch.multinomial(top_k_probs, 1)
predicted_token_id = top_k_indices[selected_idx].item()
input_ids[0, pos] = predicted_token_id
generated_text = self.tokenizer.decode(input_ids[0][1:-1])
return generated_text
if __name__ == "__main__":
generator = BertGenerator()
for _ in range(10):
sentence = generator.regenerate_from_input_without_UNK('你好,我的名字叫李华,来自湖北武汉。',random_order=False)
print(sentence)